Constraints beat prompts for AI code
13 Feb 2026Coding with AI has an entropy problem
A few hours into coding with AI, a pattern shows up. The code looks clean. Abstractions make sense. Tests pass. And yet under concurrency, your rate limiter collapses because the counter isn’t atomic.
Here’s the formula nobody talks about: failure= error rate × variance
Coding with AI massively increases variance. Even if error rate stays constant (big if), failures scale dramatically with output. After a few hours, you have 200 files of mostly okay spaghetti code and an AI who responds to your prompts with things like:

That asymmetry is the core problem.
AI systems are very good at generating plausible structure: clean abstractions, proper separation of concerns, thoughtful API boundaries. They’re weaker at adversarial edge cases, enforcing invariants, state transitions under load, and remembering decisions made hundreds of thousands of tokens ago.
I’ve spent much of the past month coding with agents and building a set of open source tools called CrossCheck to push development further. What follows is an overview of my philosophy and implementation.

This is a governance problem, not a prompting problem
Most advice about coding with AI focuses on prompts: be more explicit, ask for tests, review carefully.
That’s behavioral control. But behavioral control isn’t deterministic and decays as context grows.
So the question shouldn’t be “how do I prompt better?” but how do I design a repo where the compliant path is the path of least resistance?
This means converting norms into invariants.
Not “please run tests.” Instead, require a test script to pass or git refuses to proceed.
Not “NEVER commit secrets.” Instead, block secret patterns at commit time.
Not “don’t merge your own code.” Instead, set git branch protections to make it impossible.
Instructions are advisory. constraints are real.
Uncorrelated layers reduce failures
If Claude writes the code, writes the tests, reviews the diff, and evaluates the security scan output, you do not have four layers. You have one reasoning process with the same blind spots wearing four hats.
If a model misunderstands a concurrency primitive, that misunderstanding propagates through implementation, test design, and review commentary. Everything agrees. Everything is wrong.
Just like investing, a couple of uncorrelated checks is much more valuable than many correlated ones.
Aviation’s “swiss cheese model of accident causation”
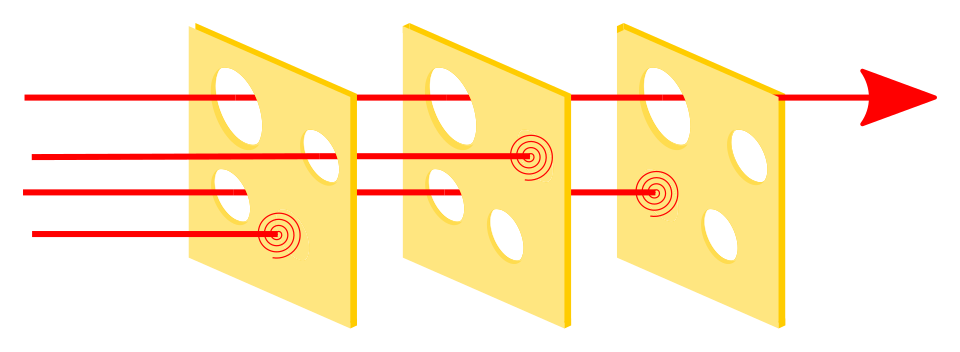
In the early jet age, planes had the nasty tendency to get lost and fly into mountains. The fix wasn’t “train better pilots.” It was layered, uncorrelated safety systems:
Pilots crosscheck independent instruments. Critical phases of flight operate under “sterile cockpit” rules where nothing unrelated is discussed. Aircraft carry multiple navigation systems: GPS, inertial reference, radio beacons that all validate each other.
Most importantly, modern aircraft connect navigation to a terrain database. If the projected flight path intersects terrain, the cockpit doesn’t politely suggest a correction. It shouts:
“Terrain… pull up.”
After incidents, black boxes reconstruct what happened; even near-misses feed back into procedures.
The result: planes are ~150x safer than driving and crashes are much “weirder” results of many errors.
Governance layers for AI code
AI development needs the same architecture as aviation safety: multiple layers, each with different strengths and weaknesses. I’ve found a few things to dramatically decrease my error rate:
-
Execution-level deny list. Destructive commands and bypass flags are permission-blocked. The agent literally cannot execute rm, sudo, –no-verify, etc. We mitigate -rm with a garbage folder the agent moves files to and the user empties occasionally.
-
Git hooks. The enforcement boundary: secrets, format, tests, protected paths.
-
Tests. Behavioral verification, invariant assertion from planning docs. Code must do what it claims under defined conditions and adversarially test against itself. I’ve also tried enforcing a CI but have been blowing through my GitHub account’s quota :/
-
Multi-model review. A model from a different lab reviews the code. Different training data, different reward tuning, different strengths and weaknesses.
-
Server-side branch protection. Identity-enforced approval. The agent account that pushes code cannot approve its own PR. Squash-only merges.
-
Give humans a place to write documents the AI can’t edit. I’ve found AI has a bad tendency to change documents that I write. I now have a section of my repos dedicated to human produced text that the AI can use as a “golden reference” and should never change. This folder is protected by a git hook.
A bug that slips past tests may not slip past a second model trained on different distributions. A secret missed by one pattern matcher may not bypass a deny list. A sloppy review cannot bypass server-side merge rules.
Git hooks as zero-trust infrastructure
AI agents regress to the path of least resistance (commit directly to main with no tests). Git hooks convert norms into invariants. They run automatically at commit, push, and merge boundaries. If a change violates policy, the repository itself refuses to move forward. Hooks enforce procedure, secrets scanning, format checks, and merge policy at commit and push boundaries while reminding the AI what it should be doing.
For solo developers, the permissions aren’t really designed to support vetting the code “you” submit so I opened a second GitHub account just for my agents. This ensures the agent account that pushes code can’t approve its own PRs and codeowners adds another gate.
The result: agents are treated like software engineers at a well permissioned company. They have total freedom on feature branches and a very scoped blast radius from others’ contributions, git history, and production systems.
AI reviews AI code
If AI writes your code, the first reviewer should not be you. It should be another model. This matters because a second model reduces correlated error, and frees you to focus on higher-leverage decisions
Every three PRs in my setup trigger a git hook enforced repo-wide assessment for bugs and security regressions.
Only scale dependably correct code
Once you have a system that writes good code, it’s time to create ways for the agents to run in a development loop without your involvement. Some best practices include:
-
Give agents tools like CLIs and MCPs. Configure once, let the agent interact programmatically. As with GitHub, I create a separate account for my agents with scoped permissions.
-
Protect the model’s context so it remains cohesive longer. Use CLAUDE.md but don’t make it too long.
-
Parallelize with git worktrees.
Protect the model’s context window
Context is a budget. Every rule, every file read, every test dump consumes tokens. As context grows, the model gets slower and starts forgetting what you told it. Heavy exploration should be delegated to subagents that return summaries.
Stale context is worse than no context. CLAUDE.md is loaded into every session so every line needs to earn its place. Mine is <100 lines and it’s supported by more detailed rules that load via hook-based triggers rather than sitting in context hoping to be remembered 200k tokens later.
Parallelize agents with git worktrees
Parallelizing development is another multiplier on your output while coding with AI. Git worktrees let you run isolated branches each with their own agents and context windows. Spin up 3-5 features in parallel, each in its own terminal tab, each with its own agent.
I combine this with a task queue: structured files the agent processes autonomously in priority order. Create branch, write code and tests, submit PR.
Numbers 001-099 are human-created tasks. 100+ are agent-created when the agent discovers follow-up work during execution. Define five tasks, review five branches of PRs an hour later.
The key: every parallel path still routes through the same structural gates. Throughput increases without sacrificing enforcement.
A warning: I tried doing this before I implemented quality gates / multi-modal checks and it took me a few days to resolve the mess :/
What’s next

Making adoption easy
This isn’t free. Setup is heavy. Token usage increases. Trivial scripts become slower. For prototypes, this is overkill. For long-lived systems, I think it’s pretty essential.
To make it easier to get started, I built my tools into an open source system called CrossCheck (link below). Let me know what you think :)
What I’m still trying to solve
Long-term memory. CLAUDE.md is static. it doesn’t know what the agent did yesterday or which tasks are blocked. the missing piece is dynamic state that persists across sessions: task graphs, dependency tracking, learned patterns.
UI loops. Backend code has clean, autonomous, easy to verify loops. UI doesn’t. You need to see the component, evaluate it aesthetically, and decide if the layout works. Screenshot-based feedback loops exist but AI’s visual judgment is unreliable. I’m urgently looking for a solution to this one. Until then all my apps will be CLIs and simple landing pages :/
Should I add a third model? Right now Claude writes and Codex reviews, but the merge-to-main step only has branch protection. Should I add Gemini? Gemini and Kimi? Where does this stop being useful?
Safer CLI access. CLIs enable loops, but many CLIs and MCPs don’t have a great way to permission access between agents and humans. We need more approval gates for destructive operations and a better way to distinguish between agents and humans in a way that doesn’t involve buying two seats for every piece of software.
Better agent permissions. We need more granularity on what parts of a git tree an agent should be able to access. I have strong main branch protections enforced on main but more nuance is needed between the branches different agents are individually working on (eg agent1 should be able to have ~unlimited permissions on branch-agent1 but agent2 running in parallel shouldn’t have any permissions there).
How I’m thinking about myself as a developer
I’ve always seen myself as a builder more than an engineer, and I haven’t had the identity crisis some of my friends are going through. The role of human judgment is still central. It’s just shifted: less typing, more governing. Less “write this function,” more “design this system.”
That’s empowering. People without specialized engineering backgrounds or the resources to hire specialists can now build things that used to be gated by both. You don’t need to be a great engineer. You need to be a great governor of systems that create software. I’ve never been more excited to build.
Standing invitation (inspired by Patio11 who also has some good tips on how to approach this): if you want to talk about hard tech or systems, I want to talk to you.
My email is my full name at gmail.com.
- I read every email and will almost always reply.
- I like reading things you’ve written.
- I go to conferences to meet people like you.
- Meetings outside of conferences are tougher to fit with my schedule - let’s chat over email first. Specificity and being concise makes it easy for me to reply :)